Observability Consulting: The Key to Modern System Reliability and Performance
In today’s fast-evolving digital landscape, organizations face unprecedented challenges in maintaining the reliability, performance, and security of their complex IT systems. As businesses increasingly adopt microservices architectures, multi-cloud environments, and container orchestration platforms like Kubernetes, traditional monitoring approaches no longer suffice. This is where observability consulting emerges as a critical discipline, empowering enterprises to gain deep, actionable insights into their systems and deliver exceptional user experiences.
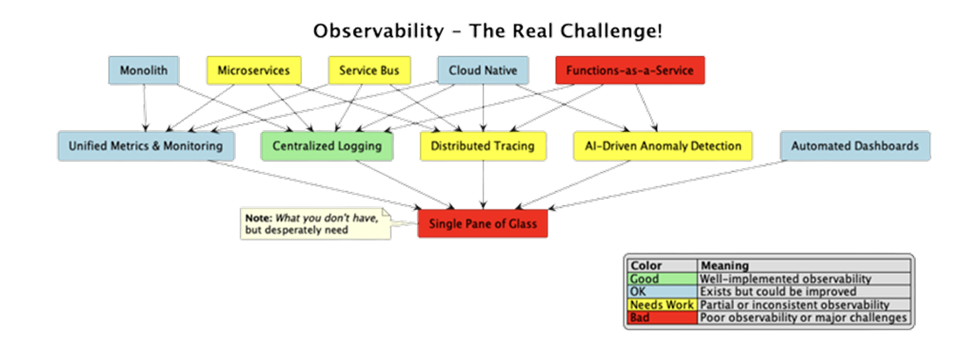
This comprehensive guide explores the importance of observability consulting, how it differs from traditional monitoring consulting, and how leading tools such as Prometheus, Grafana, Datadog, and Kibana play vital roles in building a robust observability strategy. Whether you’re a CTO, DevOps engineer, or IT leader, understanding and investing in observability consulting can transform your organization’s ability to detect, diagnose, and resolve issues faster than ever before.
What Is Observability Consulting?
At its core, observability is the ability to understand the internal state of a system based on the data it produces—metrics, logs, and traces. While monitoring consulting focuses primarily on collecting predefined metrics and setting alerts to notify teams when something goes wrong, observability consulting goes much deeper.
It equips organizations with the expertise and tools to investigate unknown issues, perform root cause analysis, and proactively optimize system health.Observability consulting involves:
- Designing and implementing observability architectures tailored to your environment.
- Integrating and configuring modern observability tools like Prometheus, Grafana, Datadog, and Kibana.
- Establishing best practices for data collection, correlation, and visualization.
- Training teams to leverage observability data for faster troubleshooting and continuous improvement.
This approach is particularly crucial for modern distributed systems where interactions between services are dynamic and complex, making static monitoring insufficient.
The Pillars of Observability: Metrics, Logs, and Traces
Effective observability relies on three foundational data types:
1. Metrics
Metrics are quantitative measurements that provide a snapshot of system performance and health. Examples include CPU usage, memory consumption, request latency, error rates, and throughput. Metrics are typically numeric and collected at regular intervals, enabling trend analysis and alerting. Prometheus consulting is often sought to implement scalable, high-resolution metrics collection. Prometheus excels at gathering time-series data and supports powerful querying via PromQL, making it a favorite among DevOps teams.
2. Logs
Logs are detailed, timestamped records of discrete events that occur within applications and infrastructure. They offer rich context about system behavior, errors, and user interactions. Kibana consulting and Kibana configuration help organizations harness the power of Elasticsearch and Kibana to index, search, and visualize log data.This enables teams to quickly identify anomalies and understand the context around incidents.
3. Traces
Traces capture the journey of individual requests as they propagate through distributed systems. They reveal dependencies, bottlenecks, and latency sources across microservices. Visualization tools like Grafana configuration and Grafana consulting enable teams to create intuitive dashboards that correlate traces with metrics and logs, providing a unified view of system health.
Observability Consulting vs. Monitoring Consulting: Understanding the Difference
| Aspect | Monitoring Consulting | Observability Consulting |
|---|---|---|
| Focus | Focus Detecting known issues via predefined metrics | Investigating unknown issues and root causes |
| Data Scope | Individual components or services | Entire distributed system |
| Approach | Reactive alerting and threshold breaches | Proactive, exploratory, and investigative |
| Outcome | Alerts and situational awareness | Deep insights, faster resolution, optimization |
While monitoring consulting remains essential for baseline system health checks, observability consulting equips teams to answer the critical “why” and “how” questions, enabling faster troubleshooting and system improvements
Why Observability Consulting Matters for Your Business
Faster Root Cause Analysis
Observability consulting enables teams to correlate metrics, logs, and traces seamlessly. This correlation dramatically reduces the mean time to resolution (MTTR) by pinpointing the exact source of issues—whether a faulty microservice, a recent code change, or infrastructure degradation.
Proactive Problem Detection
Observability uncovers “unknown unknowns” — problems that traditional monitoring misses because they don’t fit predefined patterns. With expert consulting, organizations can set up intelligent anomaly detection, alerting teams before users experience issues.
Support for Complex Architectures
As organizations adopt microservices, Kubernetes, and multi-cloud strategies, observability consulting becomes indispensable for managing dependencies, scaling efficiently, and ensuring system health across diverse environments.
Improved Collaboration Across Teams
Unified observability data fosters collaboration between developers, site reliability engineers (SREs), and operations teams. By breaking down silos, observability consulting helps create shared understanding and faster incident response.
Leveraging Leading Observability Tools with Expert Consulting
Prometheus Consulting: Mastering Metrics Collection
Prometheus is the de facto standard for open-source metrics collection. It excels at scraping high-cardinality, high-dimensional data from your systems. With Prometheus consulting, organizations receive expert guidance on:
- Designing scalable Prometheus architectures.
- Writing efficient PromQL queries.
- Integrating Prometheus with alerting systems.
- Combining Prometheus with Grafana for rich visualization.
Grafana Configuration and Consulting: Visualizing Data for Actionable Insights
Grafana is the leading open-source platform for visualizing metrics, logs, and traces. Through Grafana consulting and Grafana configuration, experts help you:
- Build custom dashboards tailored to your operational needs.
- Correlate data from multiple sources including Prometheus, Elasticsearch, and Datadog.
- Implement alerting rules and notification channels.
- Enable real-time monitoring with intuitive visualizations.
Datadog Integration and Consulting: Unified Observability as a Service
Datadog offers a comprehensive SaaS platform that integrates metrics, logs, traces, and security signals. With Datadog consulting and Datadog integration services, teams can:
- Seamlessly onboard workloads across cloud providers.
- Leverage AI-powered anomaly detection.
- Correlate infrastructure and application data.
- Optimize costs and performance with detailed analytics.

Kibana Consulting and Configuration: Unlocking Log Data Potential
Kibana, part of the Elastic Stack, is a powerful tool for searching, analyzing, and visualizing log data. Through Kibana consulting and Kibana configuration, organizations can:
- Set up Elasticsearch clusters optimized for log ingestion
- Create visualizations and dashboards that highlight critical events.
- Implement alerting based on log patterns.
- Integrate logs with metrics and traces for comprehensive observability.
Best Practices in Observability Consulting
1. Start with Clear Objectives:
Define what you want to achieve with observability—faster incident response, improved uptime, or better performance insights.
2. Adopt a Data-First Approach
Collect high-quality metrics, logs, and traces from all critical components.
3. Correlate Across Data Types:
Use tools and consulting expertise to link metrics, logs, and traces for holistic analysis.
4. Automate Alerting and Incident Response:
Implement intelligent alerting to reduce noise and focus on actionable events.
5. Continuously Iterate and Improve:
Observability is not a one-time setup. Regularly review dashboards, queries, and alerts to adapt to evolving systems.
6. Train Your Teams:
Ensure developers, SREs, and operations staff understand how to use observability tools effectively.
How Observability Consulting Drives Business Value
- Reduced DowntimeFaster detection and resolution of issues minimize service disruptions.
- Improved Customer Experience: Stable and performant systems lead to higher user satisfaction.
- Cost Efficiency: Optimized resource usage and proactive problem detection reduce operational costs.
- Agility and Innovation: With confidence in system stability, teams can deploy new features faster.
Conclusion: Elevate Your Systems with Expert Observability Consulting
In an era where digital services are mission-critical, investing in observability consulting is no longer optional—it’s a strategic imperative. By leveraging expert guidance in Prometheus consulting, Grafana configuration, Datadog integration, and Kibana consulting, organizations can transform raw data into actionable insights. This holistic observability approach empowers teams to detect issues before they impact users, perform deep root cause analysis, and continuously optimize system performance. Whether you’re managing a sprawling microservices architecture or a hybrid cloud environment, observability consulting provides the expertise and tools needed to maintain reliability, improve collaboration, and drive business success.
If you want to unlock the full potential of your systems and ensure they operate at peak performance, partnering with a trusted observability consulting provider is the smartest next step.